Word Embeddings
Word Embeddings
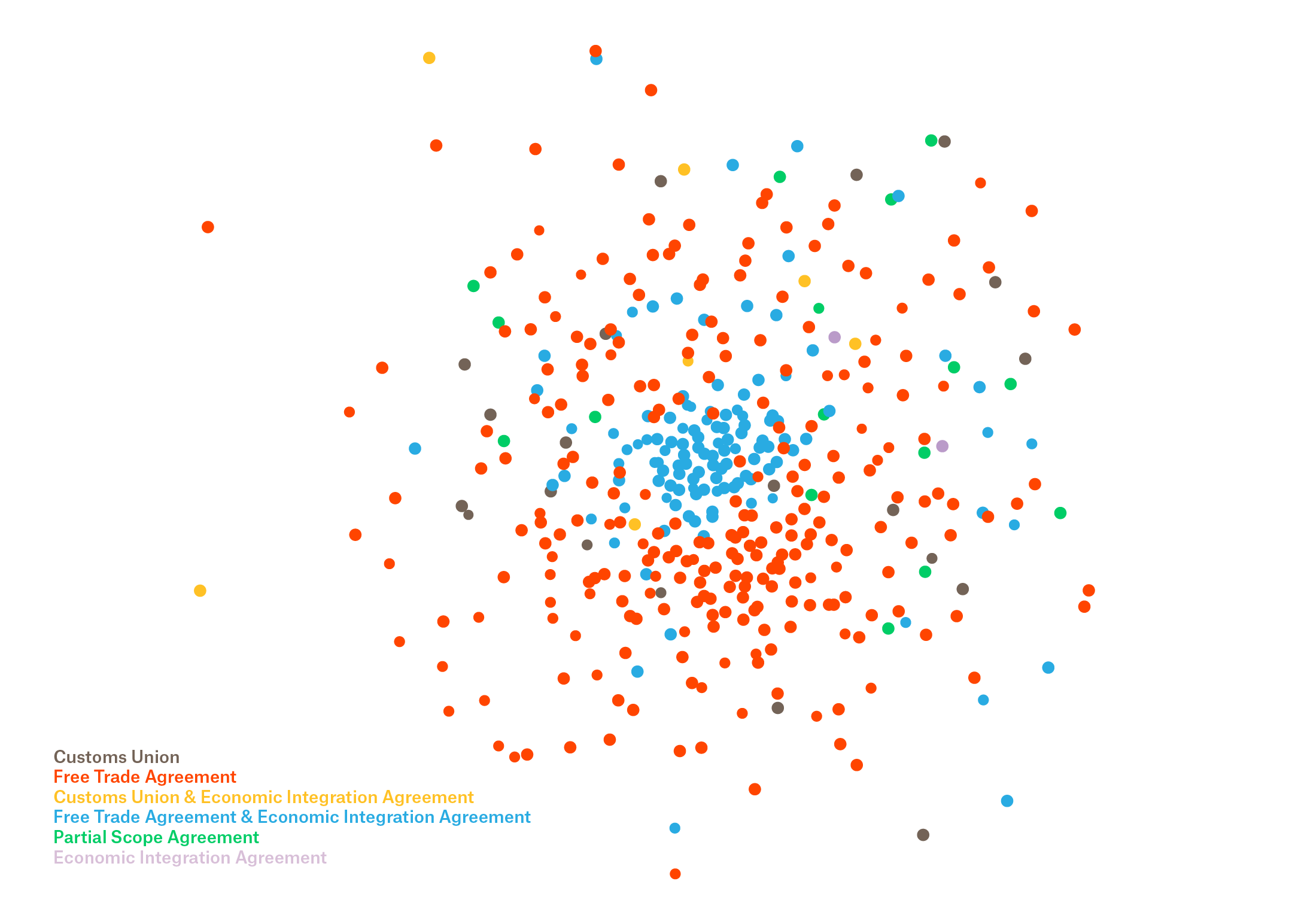
Dots representing all trade agreements. Distances between documents where extracted using Word Movers Distance based on pretrained word embedding model. Optimal 2D dot layput was achieved with 'neato' weighted springs algorithm. Two main clusters appear clearly in the center with distinct similarities between each other. It is interesting that 'Free Trade Agreements' featured in red seem to surround the 'FTA&EIA' depicted in blue. Its important to note that in this case: closeness = sameness
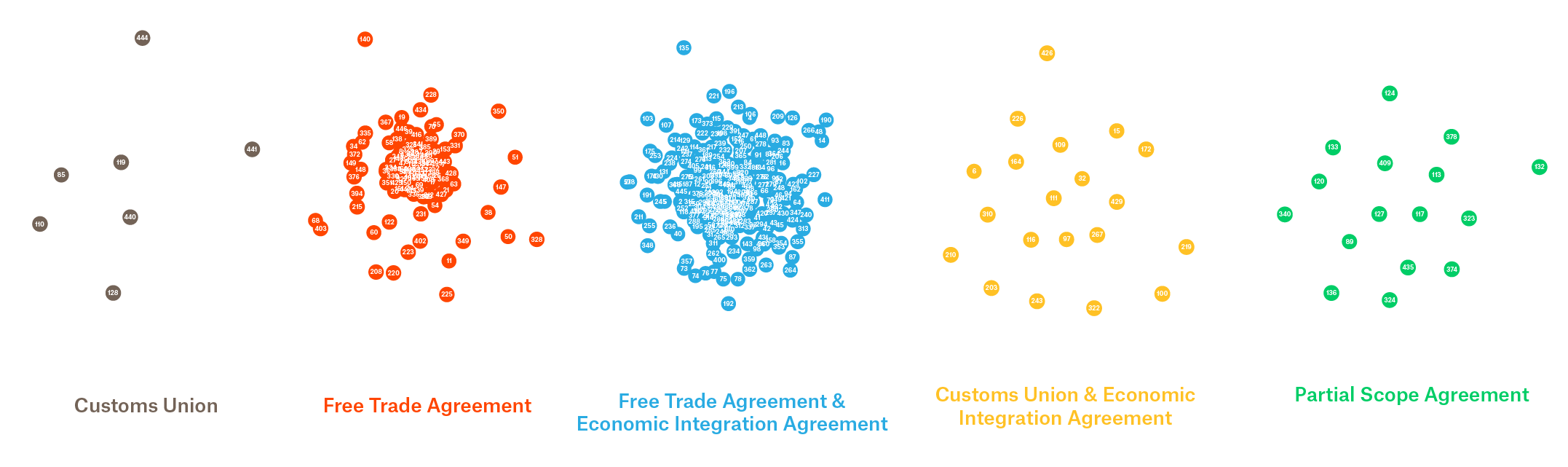
Types of trade agreements visualized by their relative distances. Scales between graphs are consistent. FTA&EIA and FTA seem to have the most similarity between elements of the same type. So we could expect to find similar meanings among these texts, it might be relevant to investigate whether they have similar consequences for the involved parties.
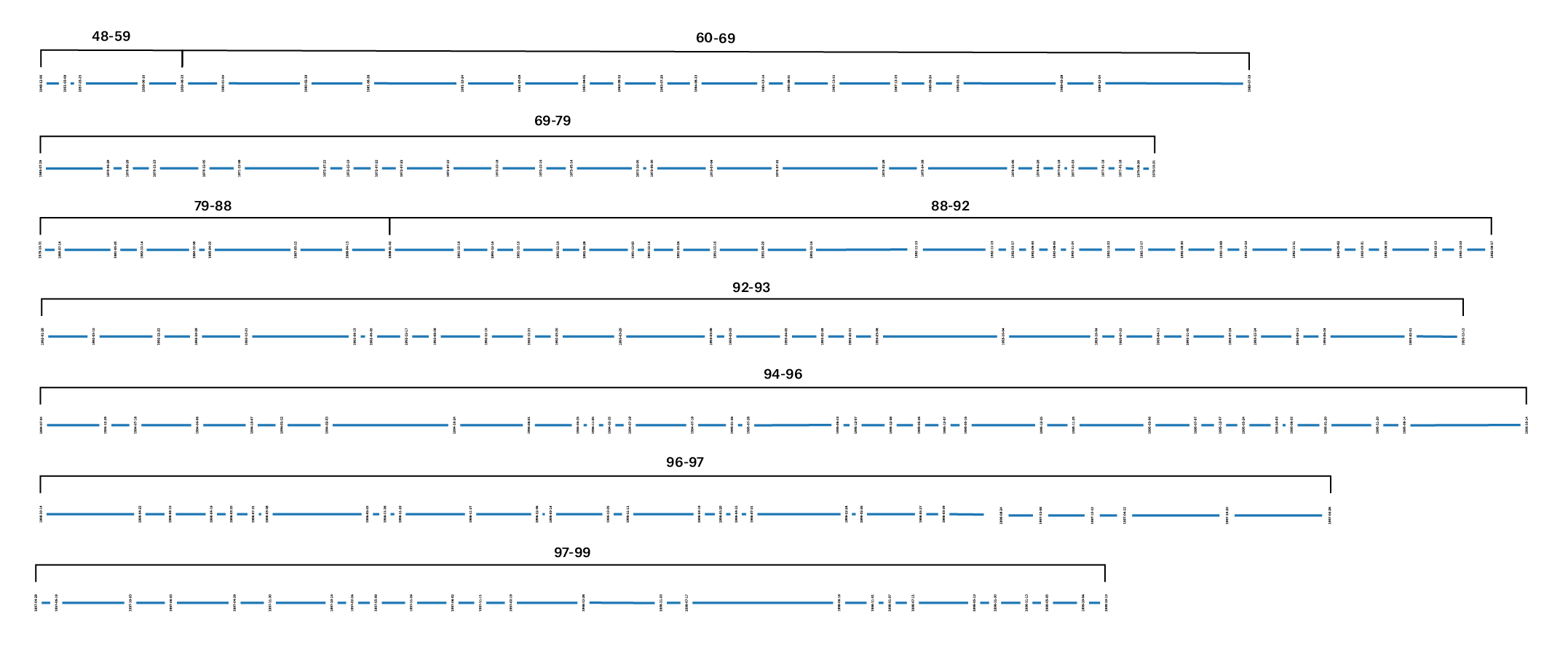
This graph shows the distance (similarity) between consecutive agreements sorted by the date they where signed. It may be worth exploring this kind of visualization in more detail. However it can be noted that the 88-92 period seems to show the most similarity between signed treaties. The main hypothesis behind this graph was look for a measure of progressiveness or economic acceleration. While the data alone will not necessarily tell us that, it is interesting to note that 92-93 period seems to show the most distance between agreements.
References:
- Ofir Pele and Michael Werman, A linear time histogram metric for improved SIFT matching, 2008.
- Ofir Pele and Michael Werman, Fast and robust earth mover's distances, 2009.
- Matt Kusner et al. From Embeddings To Document Distances, 2015.